본 정리는 CS422-컴퓨터 구조 및 설계 : 하드웨어/소프트웨어 인터페이스. David A. Patterson, 존 헤네시 책을 바탕으로 하고 있음을 미리 알립니다.
파이프라이닝을 하게 됨으로써 우리는 겪을 수 있는 문제들이 있다.
- structural hazards ( 구조 문제 ) - 같은 자원에 대한 사용을 동시에 다른 곳에서 하게 될 경우이다.
- ex) 두개의 명령어가 동시에 똑같은 메모리 구역을 읽게 될 경우
- data hazards ( 데이터 문제 ) - 데이터가 준비되기 이전에 사용되는 문제
- ex) add r1, r2, r3 이후 sub r4, r2, r1 명령어가 올 경우 r1에 데이터가 준비되기 이전에 sub 명령어가 실행되어 r1에 예상치 못한 값이 들어있게 된다.
- control hazards ( 제어 문제 ) - 조건이 확인되기 이전에 다른 명령어가 실행되는 경우
- ex) beq r1, r4, loop 이후 add r1, r2, r3 명령어가 올 경우 loop로 가게 되더라도 add 명령어가 실행되어 버린다.
모든 문제는 사실 그냥 기다리는 방식으로 해결할 수 있지만, 이는 성능에 별로 좋지 못하다.
Structure Hazards
자원에 동시에 접근해서 생기는 문제이다.

예를 들어서 다음과 같이 하나의 메모리에 동시에 접근하게 될 때 structural hazards가 생긴다.
3가지 해결법
- Waiting - load나 store처럼 메모리 접근이 필요한 명령어 사용시 3사이클 동안 명령어 사용을 하지 않고 기다려서 충돌을 방지한다 -> 성능 x
- 메모리 구역을 명령어 구역과 data 구역으로 구분하여 사용한다.
- 메모리가 읽고 쓰는 것을 한 사이클에 1 word 이상 읽고 쓸 수 있게 허용한다.
Data Hazard
sub $2, $1, $3
and $12, $2, $5
or $13, $6, $2
add $14, $2, $2
sw $15, 100($2)
위 명령어에서 어떤 오류가 발생할 수 있을까?
sub한 결과는 4사이클 후에 레지스터에 도착하는데, $2 레지스터에 도착하기 전에 and 명령어가 $2 레지스터의 값을 사용하여 계산하기 때문에 예상치 못한 결과가 발생하게 된다.
이외에도 or add에서도 마찬가지로 같은 문제가 발생한다.
즉, 데이터에 의존성이 생기게 된다.

그림으로 보면 더 이해가 잘 갈 것이다.
결과는 WB stage에서만 업데이트되기 때문에 해당 결과를 전 명령어의 WB stage 전에 혹은 동시에 사용하는 명령어들은 예기치 못한 데이터를 얻게 된다.
이를 해결하는 방법은 무엇일까?

간단한 방법은 다음에 실행하는 명령어가 WB stage 이후에 실행되게 해 주면 된다.
즉, 명령어 stall을 일으키면 되는데 이는 앞서 언급한 waiting 방식이고 성능에 좋지 못하다.
이러한 stall 없이 하는 방법에는 전방 전달(forwarding) 하는 방법이 있다.

즉, 하드웨어 설계를 통해 계산 결과가 저장된 EX/MEM 파이프라인 레지스터에서 혹은 MEM/WB 레지스터에서 계산 결과를 가져와서 쓰는 것이다.
이는 Data Forwarding 혹은 Bypassing이라고 부르기도 한다.
ALU의 rs rt 두 곳 input으로 multiplexer를 두어, 3가지 파이프라인으로부터 값을 가져오는 것을 허락하는데,
00: normal input (ID/EX pipeline registers) (원래의 값)
10: forward from previous instr (EX/MEM pipeline registers) (계산한 결과)
01: forward from instr 2 back (MEM/WB pipeline registers) (계산한 결과)
의 3가지가 된다.
그러면 언제 Forward를 하는지 어떻게 알 수 있을까?
Forward unit이 담당해서 Forward가 필요한지 탐지해서 신호를 보낸다.
언제 Forward가 필요할까?
앞선 명령어가 WB 단계에서 쓰기를 하려는 레지스터를 다른 명령어가 EX 단계에서 사용하려고 시도할 때, ALU에서는 그 값이 입력으로 필요해진다.
편의를 위해 파이프라인 레지스터의 각 필드를 EX/MEM.RegisterRd와 같이 표현하겠다.
우선은 이전 명령어 혹은 그 이전 명령어의 Control 신호가 RegWrite여야만 의존성이 생긴다.
EX/MEM.RegWrite, MEM/WB.RegWrite
추가로, rd 레지스터가 0이면 쓰질 않는다는 말이므로 rd 레지스터가 0이면 안된다.
EX/MEM.RegisterRd ≠ 0, MEM/WB.RegisterRd ≠ 0
이전 그리고 그 이전 명령어의 rd 레지스터와 내가 지금 쓰려는 rs, rd 레지스터가 같으면 이때 data harzard가 발생한다.
EX/MEM.RegisterRd = ID/EX.RegisterRs
EX/MEM.RegisterRd = ID/EX.RegisterRt #이전 명령어와의 비교
MEM/WB.RegisterRd = ID/EX.RegisterRs
MEM/WB.RegisterRd = ID/EX.RegisterRt #전전 명령어와의 비교
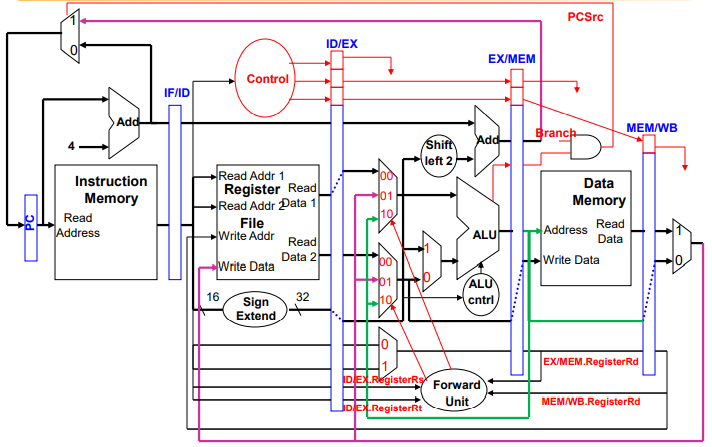
Forward unit을 포함한 하드웨어이다.
즉 위 조건을 모두 합치면,
1. EX harzard 탐지
if (EX/MEM.RegWrite
and (EX/MEM.RegisterRd != 0)
and (EX/MEM.RegisterRd == ID/EX.RegisterRs)) # rs
ForwardA = 10
if (EX/MEM.RegWrite
and (EX/MEM.RegisterRd != 0)
and (EX/MEM.RegisterRd == ID/EX.RegisterRt)) # rt
ForwardB = 10
2.MEM harzard 탐지
if (MEM/WB.RegWrite
and (MEM/WB.RegisterRd != 0)
and (MEM/WB.RegisterRd == ID/EX.RegisterRs)) # rs
ForwardA = 01
if (MEM/WB.RegWrite
and (MEM/WB.RegisterRd != 0)
and (MEM/WB.RegisterRd == ID/EX.RegisterRt)) # rt
ForwardB = 01

위와 같은 경우를 살펴보자.
마지막 명령어는 $1레지스터를 위 탐지 대로라면 첫 번째 그리고 두 번째에서도 모두 받아온다.
그러나 우리가 필요한 결과는 가장 최근에 일어난 명령어로부터 forward 하는 것이고, 이는 EX/MEM 파이프라인 레지스터로부터 값을 가져오는 것이다.
즉, 이를 위해 MEM harzard에 EX harzard가 아닐 때 수행된다는 조건을 달아주자.
if (MEM/WB.RegWrite
and (MEM/WB.RegisterRd != 0)
and (MEM/WB.RegisterRd == ID/EX.RegisterRs)) # rs
and not(EX/MEM.RegWrite and (EX/MEM.RegisterRd != 0)
and (EX/MEM.RegisterRd == ID/EX.RegisterRs)) #EX 탐지에 not만 붙여준 것이다.
ForwardA = 01
if (MEM/WB.RegWrite
and (MEM/WB.RegisterRd != 0)
and (MEM/WB.RegisterRd == ID/EX.RegisterRt)) # rt
and not(EX/MEM.RegWrite and (EX/MEM.RegisterRd != 0)
and (EX/MEM.RegisterRd == ID/EX.RegisterRt)) #EX 탐지에 not만 붙여준 것이다.
ForwardB = 01
지금까지는 산술 연산에서 데이터가 필요한 경우만 봤다.
그렇다면 Memory 접근 (load store) 명령어는 어떨까?

메모리 접근 명령어는 우선 산술 연산 명령어와는 다르게 결과가 MEM stage 이후에 나온다.
그러나 그 값이 필요한 것도 MEM stage이기 때문에 똑같은 방식으로 Forwarding 해주면 된다.

lw $2, 20($1)
and $4, $2, $5의 경우를 생각해보자.
lw stage의 결과는 MEM stage에서 나오는데, 바로 다음에 and 같은 명령어가 온다면 lw가 MEM stage일 때,
이미 and는 EX stage를 진행 중이기 때문에 MEM stage에서 나온 결과를 연산에 사용할 수 없다.
즉 이럴 때는 명령어에 1 cycle delay 주는 것이 불가피하다.

1 cycle delay 주는 방법을 stall이라 하는데, 이는 명령어가 우선은 실행되다가 Harzard Unit에 의해 stall이 필요함이 탐지되었을 때, 모든 컨트롤 신호를 0으로 바꿔 아무 역할 못하게 하고, 다음에 다시 그 명령어가 실행되게끔 한다.
Load에 의한 Harzard는 ID stage에서 이전 명령어가 Load 명령어이고, Load 명령어의 rt레지스터와 나의 rs혹은 rt 레지스터가 같을 때 탐지된다.
이를 코드로 표현하면 다음과 같다.
if (ID/EX.MemRead
and ((ID/EX.RegisterRt = IF/ID.RegisterRs)
or (ID/EX.RegisterRt = IF/ID.RegisterRt)))
stall the pipeline
즉 이러한 stall은 ID stage에서 이루어지고, stall이 일어나면 contol 신호가 모두 0이 되어 한 사이클 동안 아무 일도 일어나지 않는 것이다

이러한 해저드는 컴파일러에 의해 해결될 수도 있다.
컴파일러는 하드웨어에 의존해서 해저드를 해결하고 올바른 실행을 보장받긴 하지만, 컴파일러가 파이프라인을 이해하고, 컴파일하여 최대한 stall을 없애는 것도 중요하다.
예를 들어,
A = B + E;
C = B + F; 를 컴파일한다고 생각해보자.
lw $t1, 0($t0)
lw $t2, 4($t0)
add $t3, $t1, $t2
sw $t3, 12($t0)
lw $t4, 8($t0)
add $t5, $t1, $t4
sw $t5, 16($t0)위와 같은 컴파일된 코드에선 lw 때문에 2 cycle stall이 일어나는 반면,
lw $t1, 0($t0)
lw $t2, 4($t0)
lw $t4, 8($t0)
add $t3, $t1, $t2
sw $t3, 12($t0)
add $t5, $t1, $t4
sw $t5, 16($t0)위와 같은 코드에선 lw에 의한 stall이 전혀 없는 것을 알 수 있다.
즉, 컴파일러도 컴퓨터의 성능을 좌지우지할 수 있다.
'CS > 컴퓨터 구조' 카테고리의 다른 글
| [Chapter 4.10 컴퓨터 구조 및 설계] 예외처리 datapath, Imprecise Exceptions (0) | 2022.07.23 |
|---|---|
| [Chapter 4.9 컴퓨터 구조 및 설계] Control Hazards와 Prediction (0) | 2022.07.22 |
| [Chapter 4.7 컴퓨터 구조 및 설계] Pipelined Datapath, Pipelined Control (0) | 2022.07.20 |
| [Chapter 4.6 컴퓨터 구조 및 설계] 파이프라이닝에 대한 개관 (0) | 2022.07.20 |
| [Chapter 4.5 컴퓨터 구조 및 설계] 데이터패스 control unit, control signal (0) | 2022.07.19 |



