본 정리는 CS422-컴퓨터 구조 및 설계 : 하드웨어/소프트웨어 인터페이스. David A. Patterson, 존 헤네시 책을 바탕으로 하고 있음을 미리 알립니다.
Control Hazards
분기 명령어
- Conditional branches (beq, bne)
- Unconditional branches (j)
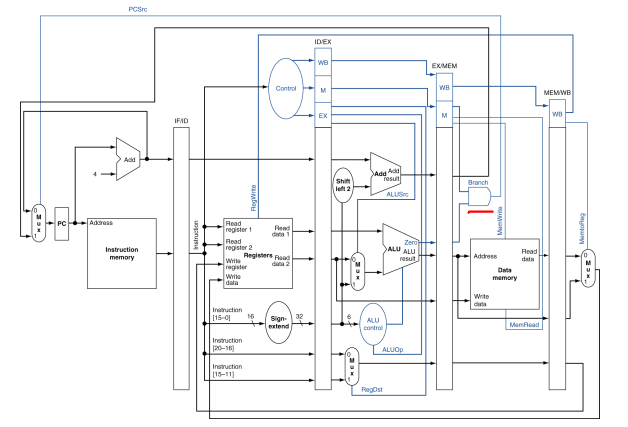
우리가 지금껏 데이터패스를 배우길 분기 명령어의 분기는 EX stage에서 판단된 후에 MEM stage에서 일어났다.

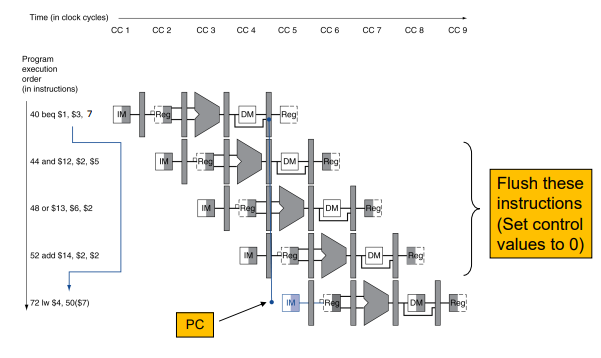
즉, 다음 3cycle 동안 오는 명령어는 모두 stall 되어야만 한다.
이 3cycle은 너무 성능을 느리게 하기 때문에 다른 방법이 필요한데, Branch decision 하드웨어를 ID stage로 옮겨오고, rs rt값을 비교해주는 compare 하드웨어를 달아서 브랜치 판단을 하는 것이다.

그러나 이렇게 하드웨어의 지원을 받아도, 판단이 ID에서 일어나 이때 다음 명령어는 IF stage에서 실행 중이므로, 1 cycle stall은 불가피하다.

정리해보면, Branch의 Target address adder를 ID stage로 끌어오고, 레지스터 Compare 유닛을 달아서 값을 ID stage에서 비교할 수 있게 되어 3cycle stall에서 1cycle stall로 바뀔 수 있게 되었다.
Data Hazards in Branch
다음 상황을 가정해보자.
add $1, $2, $3
add $4, $5, $6
beq $1, $4, target

beq명령어에선 $4의 결과 값이 필요하다.
add 명령어에서 $4의 결과값이 정해지는 것은 EX stage가 지난 이후이고, Branch 명령어는 이때 이미 ID stage가 진행되고 있다.
add 명령어의 EX/MEM 레지스터에서 데이터 Forwarding을 한다고 하더라도, beq 명령어는 이미 ID stage이기 때문에 1cycle stall이 불가피하다.
lw $1, addr
beq $1, $0, target
위와 같은 경우엔 어떠할까?
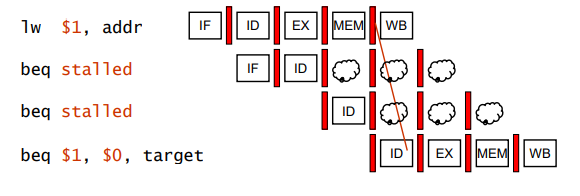
lw 명령어에서 $1의 결과값이 정해지는 것은 MEM stage가 지난 이후이고, Branch 명령어는 이때 이미 EX stage가 진행되고 있다.
add 명령어의 MEM/WB 레지스터에서 데이터 Forwarding을 한다고 하더라도, beq 명령어는 이미 EX stage이기 때문에 ID stage로 값을 받아오기 위해서 2cycle stall이 불가피하다.
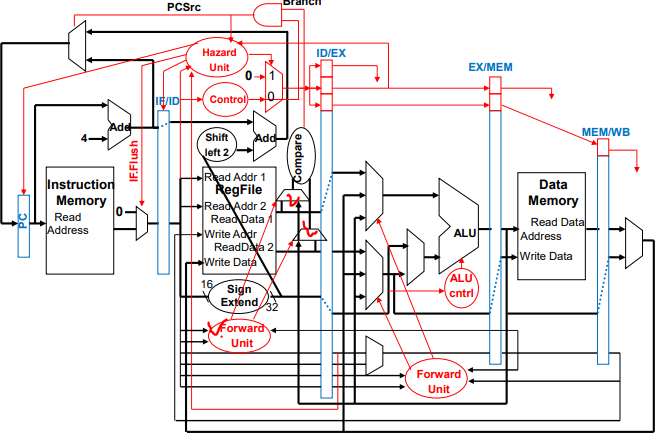
이런 Data Forwarding을 위해 Forward를 판단할 Foward unit이 ID stage에도 필요하게 된다.
Branch Prediction
무조건 branch 명령어 이후에 1cycle stall 하는 것에서 성능을 그나마 높일 수 있는 것은 예측을 하는 것이다
정적인 예측 방법에 항상 브랜치가 분기가 일어나지 않을 것이라고 예측하는 방법이 있다.

이렇게 하면 어차피 PC+4의 명령어가 실행될 것이므로, stall하지 않고도 다음 명령어를 그대로 실행하면 되고,
만약, 분기가 일어난다면 그때 1cycle stall을 해주는 것이다.
이렇게 분기가 일어나지 않을 것이라고 예측하는 것은 beq명령어가 Loop문의 상단에 있을 때, 상당히 효과적이다.
Loop: beq $1,$2,Out
1nd loop instr
.
.
.
last loop instr
j Loop
Out: fall out instrLoop문은 대부분 여러번 돌기 때문에 마지막 한번을 제외하고는 분기되지 않기 때문에 마지막 한번만 1cycle stall이 필요하게 된다.
동적인 예측 방법
동적인 예측 방법은 다음 4 과정을 거친다.
- Branch prediction buffer( branch history table이라고도 한다. )를 사용하여 최근의 브랜치 명령어의 주소를 index한다.
- 해당 브랜치 명령어의 결과( 분기 되었는지 안되었는지 - taken/not taken )를 위 버퍼에 저장한다.
- 브랜치를 실행할 때 위 테이블을 check하여 같은 결과가 나올 것이라고 예측하여 실행한다.

Branch prediction buffer는 IF stage에 존재하는데, ID stage로부터 branch가 taken되었는지 안되었는지 정보를 받아와 predition bit로 저장한다.
predition bit로 다음에 똑같은 브랜치 명령어가 들어왔을 때, 예측을 하고 예측이 맞았다면 그대로 틀렸다면 1cycle stall후 알맞은 명령어를 실행 후 prediction bit도 바꿔준다.
Branch prediction buffer는 브랜치가 taken 될지 안될지 예측할 뿐 해당 예측이 맞았을 때 어떤 주소로 갈지 정보를 갖고 있지 않은데 이 정보는 branch target buffer (BTB)가 갖고 있다.

이 두가지 버퍼를 통해 우리는 예측이 맞았을 때 더 이상 stall을 할 필요가 없어지게 된다.
위 예시는 1-bit predict를 하였는데 2-bit를 사용하여 정확도를 90퍼센트까지 끌어올릴 수도 있다.
2-bit Predictors는 두번 예측이 틀렸을 때만, prediction bit가 바뀌게 된다.

delay slot
브랜치 이후에 stall이 되는 cycle을 delay slot이라고 하자.
이 delay slot에 브랜치와 전혀 상관 없는 명령어를 넣는 스케줄링을 한다면 stall을 피할 수 있다.

또 브랜치의 target address에 있는 명령어를 복사해서 오는 방법도 있다.

즉 if 전이나 후나 무조건 실행될 명령어기 때문에 복사해 온 것인데, 이는 명령어의 개수 자체를 증가시키기 때문에 전혀 상관없는 명령어를 가져오는 것이 가장 효율이 좋은 방법이라고 할 수 있다.
Jump
Jump 명령어는 무조건 해당 address로 점프하라는 뜻이다.
PC+4와 Jump address add를 ID stage에서 할 수 있게끔 하드웨어를 ID stage로 가져오면 ID stage에서 분기될 수 있다.
그러나 Branch 명령어와 마찬가지로 Jump 명령어가 ID stage에서 실행 중 일때 이미 PC+4의 명령어가 IF에서 실행 중일 것이므로 1 cycle stall이 불가피하다.




