본 정리는 운영체제(Operating System: Concepts) 9th edition과 22학년도 1학기 건국대학교 운영체제 수업을 바탕으로 하고 있습니다.
앞에까지의 스케줄링은 단일 처리기 시스템(CPU가 하나만 있는 시스템)에서의 CPU 스케줄링이었다.
현대에는 대부분 CPU가 여러 개인 다중 처리기 시스템을 사용한다.
다중 처리기 시스템에서의 스케줄링을 알아보자.
다중 처리기 스케줄링 (Multiple-Processor Scheduling)
다중 처리기에서는 부하 공유(load sharing)가 가능해진다.
* 부하 공유 : 쉬고 있는 처리기에 할 일을 부여하는 것. 한 처리기는 계속 일하고 나머지는 놀고 있는 상태가 되어서는 안 된다.
하지만 이에 따라 스케줄링은 더 복잡해진다.
동일한 다중 처리기일지라도 때로는 스케줄링에 어떠한 제한 사항이 걸려있을 수 있기 때문이다.
ex) 어떤 프로세스는 특정 프로세서의 버스에만 부착된 입출력 장치를 사용해야만 할 때 반드시 해당 프로세서에서 처리되도록 스케줄링되어야 한다.
최상의 스케줄링 방법은 아직도 연구 중이라고 한다.
현재는 다중 처리기 스케줄링에 대한 접근 방법에는 두 가지가 존재한다.
1. 비대칭 다중 처리(Asymmetric Multiprocessing)
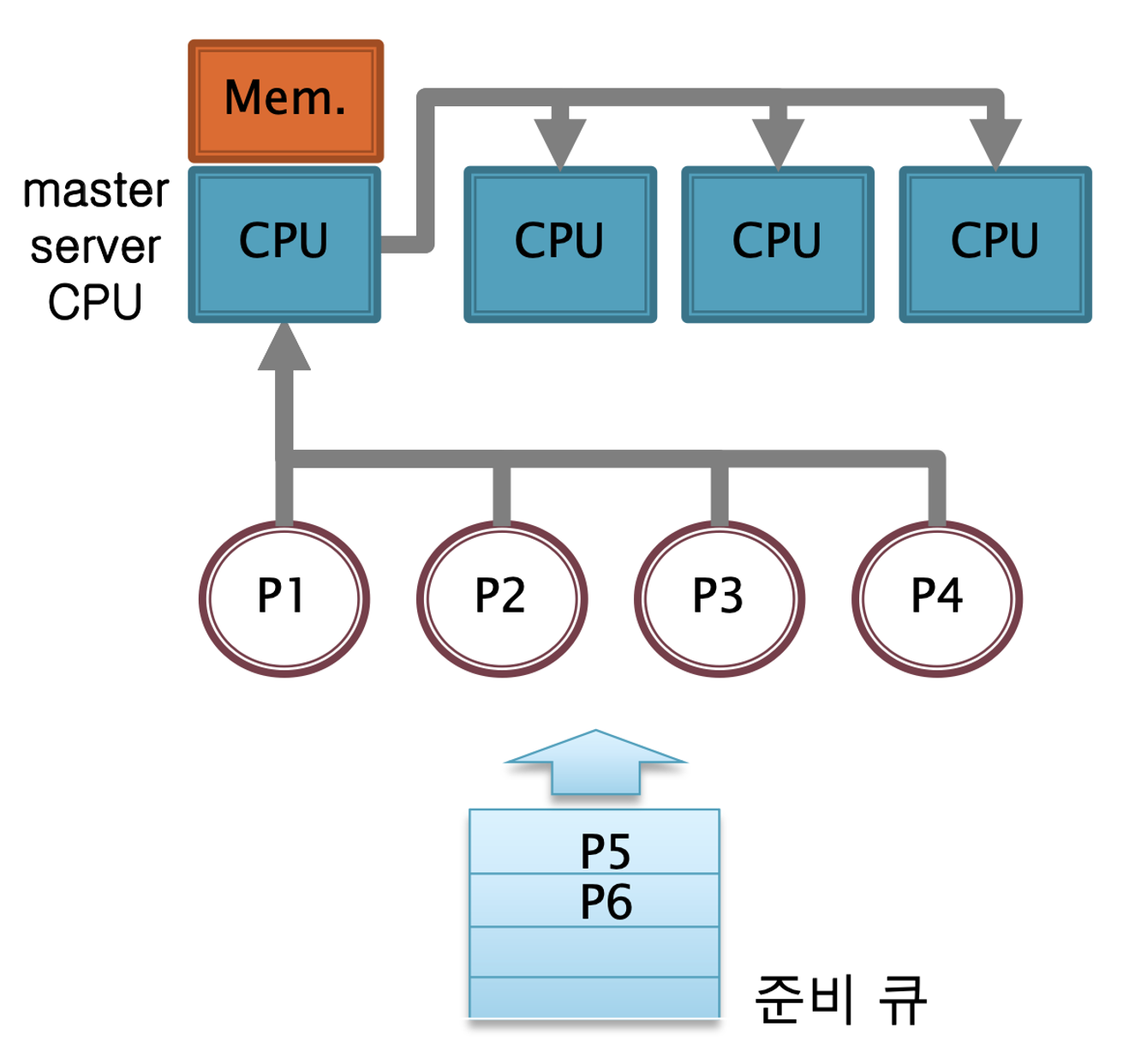
주 처리기(master server)가 모든 스케줄링 결정, 입출력 처리, 다른 시스템 활동을 취급한다.
다른 처리기들은 사용자 코드만을 수행한다.
한 처리기만 시스템 자료구조를 접근하기 때문에 처리기 간에 커널 내 자료를 공유할 필요가 없다. (자료 공유의 필요성을 배제)
따라서 상호 배제 문제에서는 자유로우며 전반적으로 단순하다.
* 상호 배제 문제 : 서로 다른 프로세스가 공유 불가능한 자원을 동시에 사용하는 것에 대한 문제
하지만 처리기 간에 부하가 불균등해지고, (주 처리기의 부하 多)
주 처리기에 문제가 생기면 시스템 전체로 문제가 확산된다는 문제점이 존재한다.
2. 대칭 다중 처리 (Symmetric Multiprocessing, SMP)
각 처리기가 독자적으로 스케줄링을 수행한다.
모든 프로세스는 공동의 준비 큐에 있거나, 각 처리기마다 가지고 있는 사유의 준비 큐에 존재하게 된다.

각 처리기의 스케줄러가 준비 큐를 검사하여 자신이 실행할 프로세스를 선정하여 수행시킨다.
따라서 각각의 스케줄러가 공동의 자료에 접근하거나 갱신을 하게 되기 때문에 신중한 스케줄링이 필요하다.
즉, 서로 다른 처리기가 같은 프로세스를 선택하지 않아야 하며, 프로세스들이 큐에서 사라지지 않는다는 것을 보장해야 한다.
거의 모든 현대 운영체제들은 이 SMP를 지원한다.
SMP 시스템은 여러 처리기가 동시에 공유 자료에 접근할 수 있으므로, 신중한 스케줄링이 필요하다.
이로 인해 나타나는 이슈들과 해결법에 대하여 알아보도록 하자
처리기 친화성 (Processor Affinity)
프로세스의 처리기 이주를 제한하고 같은 처리기에서 계속 실행시키려 하는 성질이다.

프로세스가 다른 처리기로 이주하여 스케줄링된다면, 각 처리기의 cache memory 갱신 비용이 낭비가 된다.
만약, 동일 처리기에서 계속 스케줄링 된다면 캐시 데이터를 이용하여 더 빠른 처리가 가능할 것이다.
이러한 비용 낭비를 줄이기 위해 처리기 친화성 특성을 사용한다.
1. 연성 친화성 (Soft Affinity)
운영체제가 동일한 처리기에서 프로세스를 실행시키기 위한 정책을 가지고 있지만 이를 보장하지는 않으며,
프로세스가 처리기 사이에서 이주를 하는 것이 가능하다.
2. 강성 친화성 (Hard Affinity)
프로세스는 시스템 콜을 통해서 자신이 실행될 특정 처리기 또는 처리기 집합을 명시할 수 있다.
ex. Linux의 sched_setaffinity()
시스템의 메인 메모리 구조가 처리기 친화성에 영향을 줄 수 있다.
비균등 메모리 접근(Non-Uniform Memory Access, NUMA) 구조의 경우를 보자.
NUMA에서는 보드들이 병렬로 장착되는데,
CPU와 메모리가 같은 보드에 존재한다면 다른 보드의 메모리보다 빠르게 접근할 수 있다.
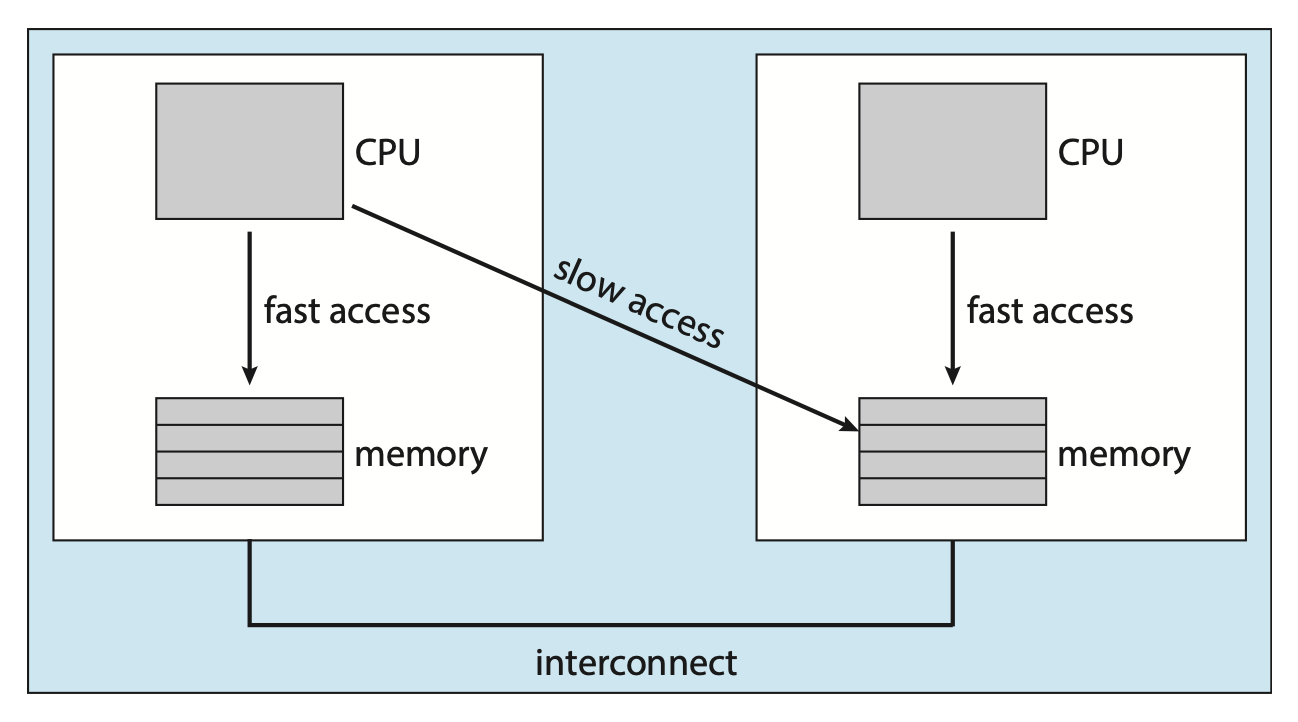
따라서 특정 CPU에 친화성을 갖는 프로세스를 해당 CPU와 같은 보드의 메모리에 배치하는 것을 통해 성능을 향상할 수 있다.
부하 균등화 (Load Balancing)
SMP 시스템에서는 모든 처리기가 균등한 부하를 갖는 것이 중요하다.
각 처리기가 자신만의 큐를 가지는 SMP의 경우 두 가지 균등화 방안이 존재한다.
1. Push 이주 (Migration) - 특정 태스크가 주기적으로 각 처리기의 부하를 검사하다 불균형 상태일 경우 다른 처리기로 프로세스를 이주
2. Pull 이주 - 쉬고 있는 처리기가 부하가 높은 처리기를 기다리는 프로세스를 Pull 하여 이주
두 가지 방식을 모두 사용하여 병렬적으로도 구현이 가능하다.
부화 균등화는 위의 처리기 친화성과 상충되는 개념으로 절대적이지 않다.
같은 CPU에 처리기 친화성을 가진 프로세스가 몰려있어서 해당 CPU의 부하가 높아지면 처리기 친화성을 무시하고, 부화 균등화 처리를 할 수도 있는 것이다.
위 상충에 대하여 절대적 규칙은 존재하지 않는다.
다중 코어 프로세서 (Multicore Processors)
하나의 프로세서 칩 내에 여러 처리기 코어를 내장한 것이다.
SMP 보다 속도도 빠르고 전력 소모도 적다.
OS 입장에서는 SMP 시스템과 동일하다
하지만, 프로세서가 메모리에 접근할 때 데이터가 가용해지기를 기다리면서 많은 시간을 허비하게 되는데 이를 Memory stall이라고 부른다.

이를 해결하기 위해서 다중 스레드 프로세서 코어를 사용하여, 둘 또는 그 이상의 하드웨어 스레드를 각 코어에 할당하여 한 스레드가 메모리를 기다리면서 멈추게 되면 코어는 다른 스레드로 전환하여 작업을 계속 수행할 수 있도록 한다.

운영체제 입장에서는 각 하드웨어 스레드는 소프트웨어 스레드를 실행할 수 있는 논리 프로세서들로 보인다.
즉, n 스레드 m 코어 프로세서에서는 n*m개의 논리 프로세서가 존재하는 것으로 인식하게 된다.
처리기를 다중 스레딩 하는 방법은 두 가지가 있다.
1. 거친(coarse-grained) 다중 스레딩
스레드가 메모리 멈춤과 같은 긴 지연시간을 가진 사건이 발생할 때까지 한 처리기에서 작업을 계속 수행한다.
긴 지연시간이 발생하면 처리기는 다른 스레드로 전환하게 된다.
하지만 다른 스레드가 수행되기 전에 명령어 파이프라인이 완전히 정리되어야 하기 때문에
스레드 간 교환 비용이 많이 든다는 단점이 존재한다.
2. 세밀한(fine-grained) 다중 스레딩
명령어 사이클 경계(명령어 주기의 종료 시점)에서 스레드 교환이 일어난다.
이 시스템의 구조적 설계에는 스레드 교환을 위한 회로를 필요로 하며,
이 회로를 통해 스레드 간의 교환 비용이 감소한다.
2레벨 스케줄링

멀티스레드-다중 코어 프로세서는 기본적으로 두 레벨의 스케줄링이 필요하다.
레벨 1) 어느 소프트웨어 스레드가 하드웨어 스레드(논리적 프로세서)에서 실행될지 결정
레벨 2) 각 코어가 어느 하드웨어 스레드를 실행토록 할지 결정
'CS > 운영체제' 카테고리의 다른 글
| [Chapter 6. 프로세스 동기화] 생산자 소비자 문제로 보는 원소적 실행과 임계 구역 (0) | 2022.09.06 |
|---|---|
| [Chapter 5. CPU 스케줄링] 실시간 시스템과 실시간 스케줄링 (RM, EDF) (0) | 2022.09.04 |
| [Chapter 5. CPU 스케줄링] 스레드 스케줄링 (0) | 2022.08.25 |
| [Chapter 5. CPU 스케줄링] 동적 우선순위와 선점 스케줄링 (라운드 로빈, 다단계 큐, 다단계 피드백 큐) (0) | 2022.08.24 |
| [Chapter 5. CPU 스케줄링] 비선점 스케줄링 FCFS,SJF,우선순위 (0) | 2022.08.23 |



