본 정리는 운영체제(Operating System: Concepts) 9th edition과 22학년도 1학기 건국대학교 운영체제 수업을 바탕으로 하고 있습니다.
앞서 비선점 스케줄링에는 무엇이 있는지 살펴보았다.
하지만 현대에는 거의 시분할 시스템으로 이루어져 있고, 시분할 시스템에서는 타임슬라이스에 의한 CPU 선점이 일어나기 때문에 이번엔 선점 스케줄링에 대하여 알아보도록 하자.
선점 스케줄링
선점이란, 실행중인 프로세스가 자신이 원하는 시점(입출력 혹은 어떤 이벤트)에 의하여 CPU 사용을 반납하는 것이 아니라 시분할 시스템에서의 타임 슬라이스 소진되거나 자신이 예상치 못한 인터럽트에 의해 CPU를 반납하게 되는 것을 선점이라고 한다.
이때, 대기 중인 프로세스 중에 우선순위를 정하고, 가장 높은 우선순위를 가진 프로세스가 다음으로 CPU 선점하게 된다.
동적 우선순위와 가변 타임 슬라이스
이때, 우선순위가 정적이라면 어떨까?
분명, 우선 순위가 높은 프로세스만 지속적으로 실행되게 될 것이다.
이에 따라, 프로세스의 실행 중에 시스템의 성능, 프로세스의 특성 등을 고려하여 우선순위를 재조정하는 동적 우선순위를 갖게된다.
시분할 시스템에서는 타임 슬라이스(프로세스가 한 번에 CPU를 점유하는 시간)도 동적 우선순위에 따라서 변하게 된다.

*타임 슬라이스가 가변적으로 변하게 되면 Clock Interrupt Interval(타임 슬라이스보다 더 짧은 주기로 시간을 체크한다)이 추가되어 타임슬라이스가 전부 소진되었는지 확인하게 된다. 매우 짧은 주기의 Clock Interrupt가 몇 번 진행되었는지 확인하여 타임 슬라이스가 소진되었는지 확인하는 것이다.
1. 대화성이 적다 = CPU-Bound Process에 가깝다
따라서 우선순위를 낮추고, 타임 슬라이스를 짧게 줘서 프로세스가 CPU를 오래 붙들고 있지 않도록 한다.
2. 대화성이 높다 = 입출력이 자주 일어난다 = I/O-Bound Process에 가깝다
이 프로세스에게는 CPU를 할당해줘도 곧 입출력이 일어나서 CPU를 자진 반납하게 될 것이기 때문에, 타임 슬라이스를 충분히 주는 것이 대화성을 높이는 것이다.
따라서 우선순위를 높이고, 타임 슬라이스도 충분히 받도록 한다.
이는 두 가지의 관점이 모두 반영되어 있는 정책이며,
1. CPU를 여러 프로세스가 공정하게 나눠 쓰게 하자는 관점
2. 대화성을 높여주자는 관점
우선순위의 변화에 따라 타임 슬라이스의 양도 변한다는 것을 확인할 수 있다.
라운드 로빈 스케줄링 (Round-Robin Scheduling)
RR 스케줄링이라고도 한다.
FIFO 스케줄링에서 선점이 추가된 스케줄링이라고 볼 수 있다.
즉, 모든 프로세스가 한 타임 슬라이스씩을 실행하고, 다시 queue에 추가되고, 가장 먼저 queue에 들어온 프로세스가 실행되고 하는 방식이 반복된다.
구현 : 원형 큐(circular queue)
준비 큐를 원형 큐로 간주하고, 새로운 프로세스들은 원형 큐의 꼬리에 추가된다.
이 큐에서 순환식으로 한 프로세스에게 작은 단위의 시간량(타임 퀀텀, time quantum)만큼씩 CPU를 할당한다.
* 타임 퀀텀은 타임 슬라이스와 같은 개념이다. (10ms ~ 100ms)
즉, 실행 상태의 프로세스가 타임 퀀텀이 지나면 선점되는 것이다. (선점형 스케줄링)
준비 큐에 n개의 프로세스가 있다고 하고 타임 퀀텀이 q라 하면, 문맥 교환 시간을 고려하지 않을 때, 모든 프로세스가 (n-1)q시간 동안 실행되므로, 이론상으로는 n개의 프로세스가 1/n의 속도로 동시에 실행된다.
평균 반환 시간과 평균 대기 시간이 SJF 스케줄링보다 길지만,
모든 프로세스가 CPU를 할당의 기회를 공정하게 얻기 때문에 기아상태는 발생하지는 않는다.
단점
1. 잦은 문맥 교환 오버헤드로 처리율(throughput)이 감소할 수 있다.
2. 타임 퀀텀의 크기에 성능이 영향을 많이 받는다.

타임 퀀텀이 짧아질수록 문맥 교환 횟수가 늘어나는 것을 확인할 수 있다.
타임 퀀텀이 매우 크다면 모든 프로세스가 자신의 할 일을 다 마치고 다음 프로세스에 CPU를 넘길 것이기 때문에 FCFS와 다를 바가 없어지고, 타임 퀀텀이 작으면 문맥 교환 오버헤드가 줄어들 것이다.
타임 퀀텀과 평균 반환 시간의 관계를 살펴보자.
타임 퀀텀이 증가하면, 시간이 조금 걸리는 프로세스는 먼저 끝낼 수 있음에도 불구하고 시간이 오래 걸리는 프로세스와 동시에 실행되어 느리게 끝나므로 평균 반환 시간이 줄어들 것으로 예상할 수 있다.
CPU 버스트 타임이 10인 3개의 프로세스 A, B, C가 있다고 하자.
1. 타임 퀀텀이 1인 경우

평균 반환 시간 = (28 + 29 + 30) / 3 = 29
2. 타임 퀀텀이 10인 경우

평균 반환 시간 = (10 + 20 + 30) / 3 = 20
위 예에서 볼 수 있듯이 타임 퀀텀을 증가하면 반환시간이 짧아지는 것을 볼 수 있다.
그러나, 많은 짧은 작업이 긴 작업들보다 순서상 늦게 처리되는 경우가 생길 수 있기 때문에 타임 퀀텀이 증가한다 해서 반드시 평균 반환시간이 개선되는 것은 아니다.
아래 그림은 타임 퀀텀에 따른 평균 반환 시간을 나타낸 그래프이다.
타임 퀀텀이 3에서 5로 증가할 때 평균 반환 시간도 같이 증가하는 것을 볼 수 있다.

대부분의 프로세스들이 한 타임 퀀텀 내에 하나의 CPU 버스트를 끝낸다면 평균 반환 시간은 개선된다.
따라서 경험적으로 타임 퀀텀은 프로세스들의 CPU 버스트들 중 80% 정도보다 길도록 조정하는 것이 좋다.
다단계 큐 스케줄링 (Multilevel Queue Scheduling)
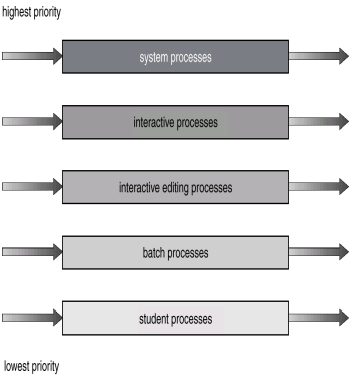
우선순위마다 준비 큐를 만들어두고, 항상 가장 높은 우선 순위 큐의 프로세스에 CPU를 할당한다.
프로세스의 성격에 따라 우선순위를 부여한다. (ex 1 시스템 작업/ 2 대화형 작업..)
각 큐는 라운드 로빈을 사용하거나 FCFS 등 독자적인 스케줄링 기법을 사용할 수 있다.
선점형 스케줄링으로 타임 슬라이스마다 상위 우선순위 큐부터 프로세스가 있는지 확인하게 된다.
다단계 피드백 큐 스케줄링 (Multilevel Feedback Queue Scheduling)
다단계 큐 스케줄링에서는 프로세스들이 영구적으로 하나의 준비 큐에 할당되었다.
이와는 다르게, 다단계 피드백 큐 스케줄링에서는 프로세스가 큐들 사이를 이동하는 것을 허용한다.
즉, 프로세스에 동적인 우선순위의 변화를 허용하는 것이다.

우선 프로세스가 처음으로 시스템에 진입했을 때에는 최상위 큐에 삽입한다.
만약 실행 중인 프로세스가 자꾸 모든 타임 슬라이스를 소진하여 CPU 시간을 너무 많이 사용한다면
한 단계씩 밑으로 내려보내, 하위 큐의 뒤로 삽입한다. (CPU-bound 프로세스)
만약 하위 큐에 있는 프로세스가 타임 슬라이스를 다 소진하지 않고 대기 상태로 돌아가면서 CPU를 반납한다면
상위 큐에 삽입하여 위로 거슬러 올라가도록 한다. (I/O bound 프로세스)
따라서 하위 큐로 갈수록 CPU-bound 프로세스임을 볼 수 있으며,
가장 하위 큐는 FCFS로 스케줄링을 실행한다
맨 아래 큐에서 너무 오래 대기하면 다시 상위 큐로 이동한다. (기아 상태 예방하는 에이징 기법)
가장 일반적으로 많이 사용되는 방법이지만, 적용하기에 아래의 요소들을 고려한 매우 복잡한 판단을 내려야 한다.
- 큐의 개수
- 각 큐를 위한 스케줄링 알고리즘
- 한 프로세스를 높은 우선순위 큐로 올려주는 시기를 결정하는 방법
- 한 프로세스를 낮은 우선순위 큐로 강등시키는 시기를 결정하는 방법
- 프로세스가 서비스를 필요로 할 때 프로세스가 들어갈 큐를 결정하는 방법
'CS > 운영체제' 카테고리의 다른 글
| [Chapter 5. CPU 스케줄링] 다중 처리기 스케줄링 (0) | 2022.08.26 |
|---|---|
| [Chapter 5. CPU 스케줄링] 스레드 스케줄링 (0) | 2022.08.25 |
| [Chapter 5. CPU 스케줄링] 비선점 스케줄링 FCFS,SJF,우선순위 (0) | 2022.08.23 |
| [Chapter 5. CPU 스케줄링] 스케줄러와 CPU 스케줄링, CPU burst time (0) | 2022.08.22 |
| [Chapter 4. 스레드] 스레드와 관련한 문제들 (0) | 2022.08.21 |



